信道编码仿真实验:从卷积码到Turbo码
信息论课程大作业,用C/C++实现卷积码和Turbo码的译码算法,在AWGN信道下对比BER性能。
本文是《信息论与信道编码》课程的综合仿真实验记录。项目覆盖了卷积码与 Turbo 码的核心译码算法,通过不同码型、判决方式、迭代次数和码长的对比实验,直观理解 AWGN 信道下各编码方案的 BER 性能差异。
综合性能对比
下图展示了四种主要编码/译码方案的性能阶梯:
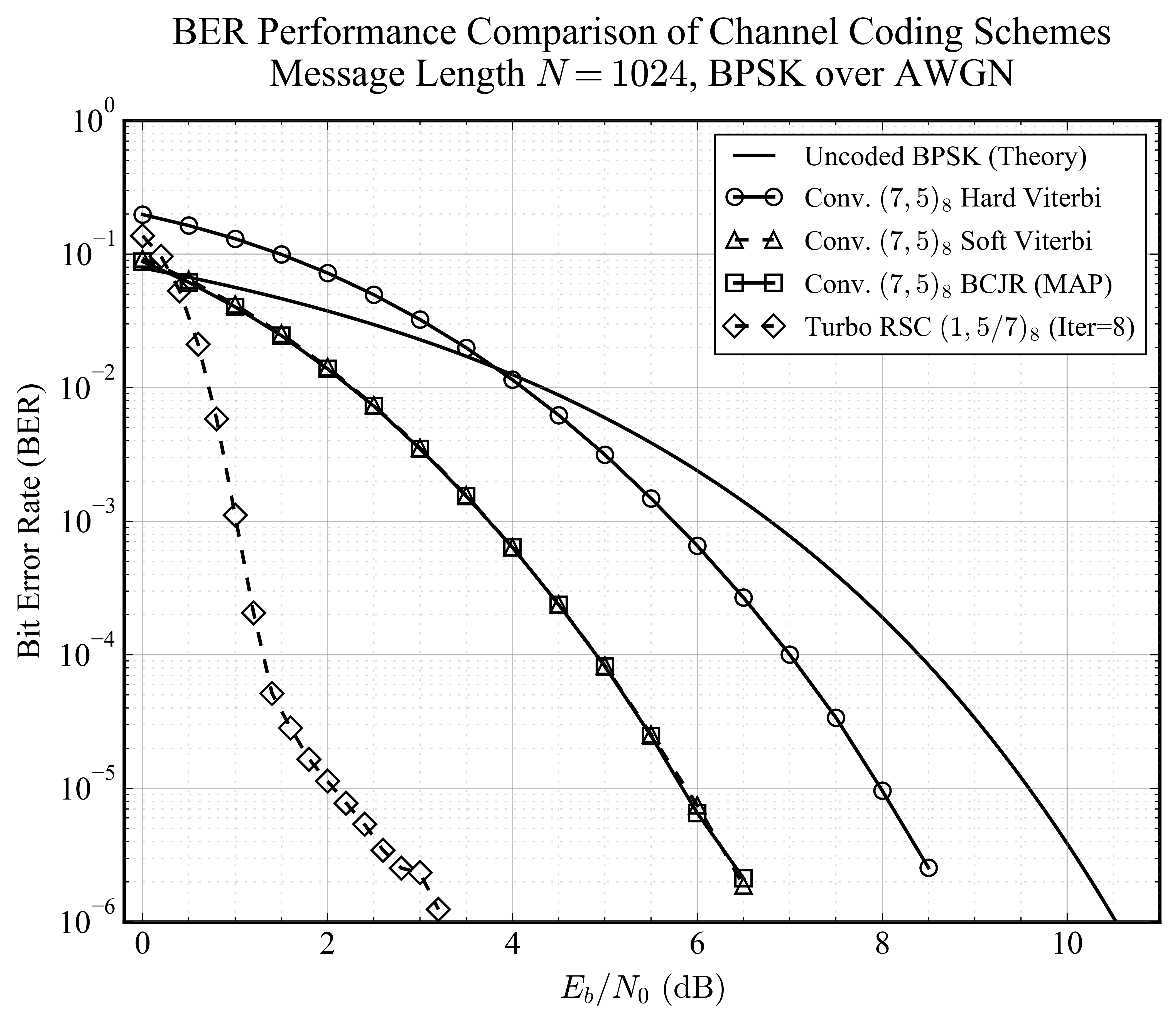
- Uncoded:未编码 BPSK,作为性能基准。
- Hard Viterbi:卷积码硬判决译码,提供基础编码增益。
- Soft Viterbi:卷积码软判决译码,相比硬判决有约 2dB 的显著增益。
- BCJR (MAP):最大后验概率译码,理论最优的软输出算法。
- Turbo Code:采用迭代译码,在低信噪比下表现出极其陡峭的瀑布区。
卷积码性能分析
实验对比了不同约束长度 K 和不同码结构(系统码/非系统码)在不同译码算法下的表现。
硬判决 Viterbi
对比 K=3 的 (7,5)、K=4 的 (15,13) 以及 RSC 递归系统码在硬判决下的性能。
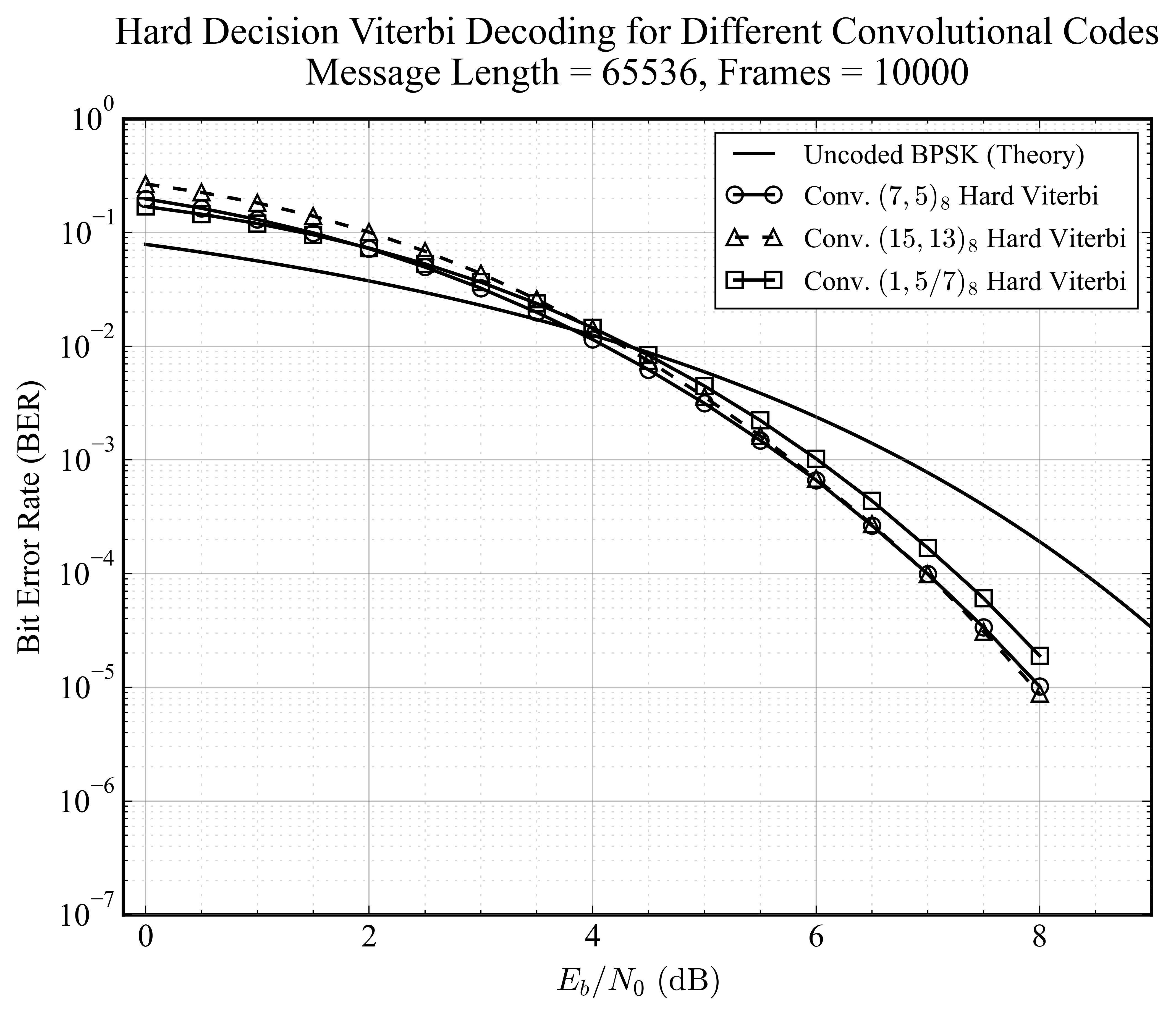
随着约束长度 K 从 3 增加到 4,编码器的记忆深度增加,纠错能力增强,BER 曲线整体左移。
软判决 Viterbi
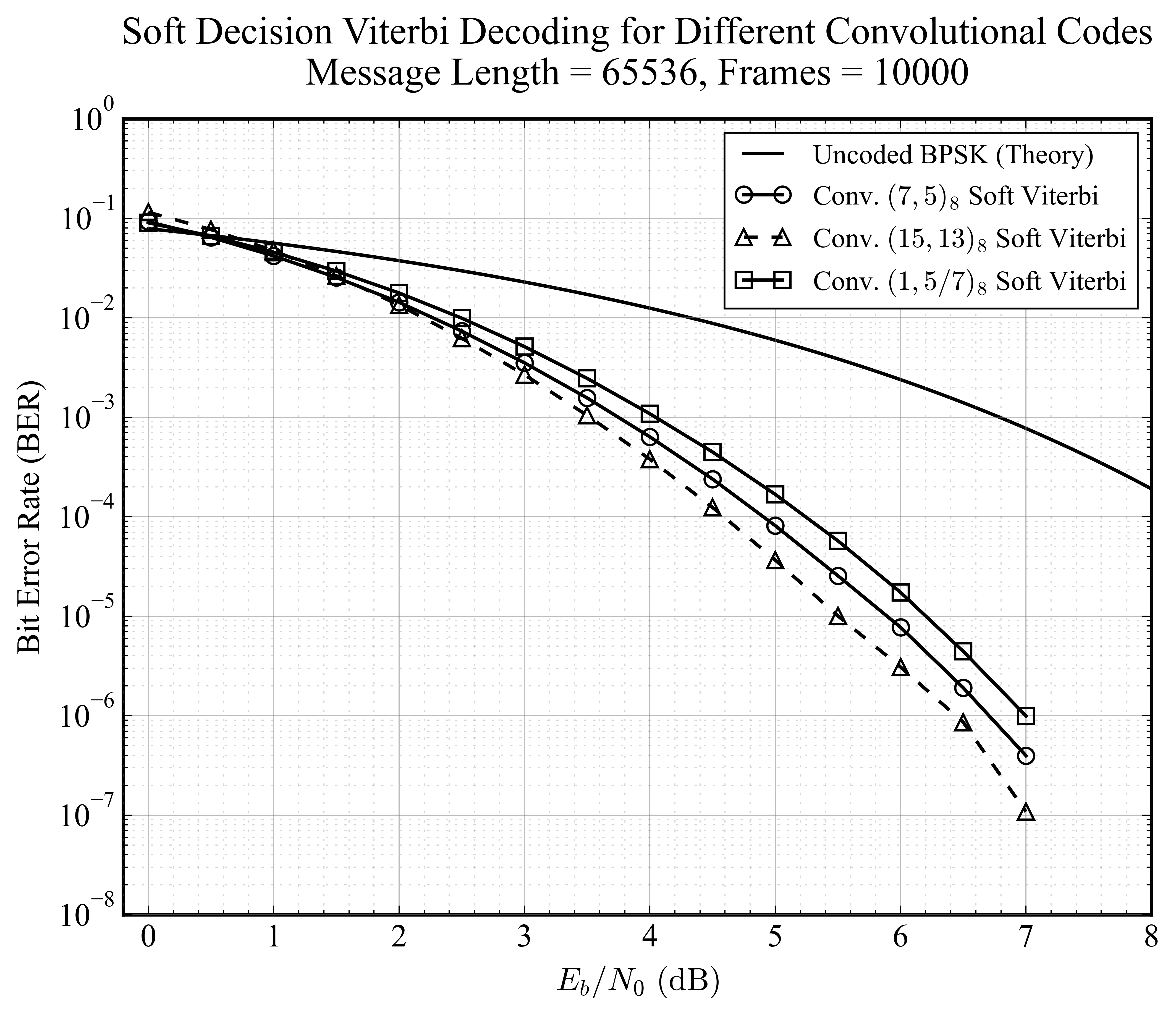
软判决充分利用了接收端的信道可靠性信息。与硬判决相比,所有码型的性能均有大幅提升,且 K=4 的优势在软判决下依然保持。
BCJR (MAP) 算法
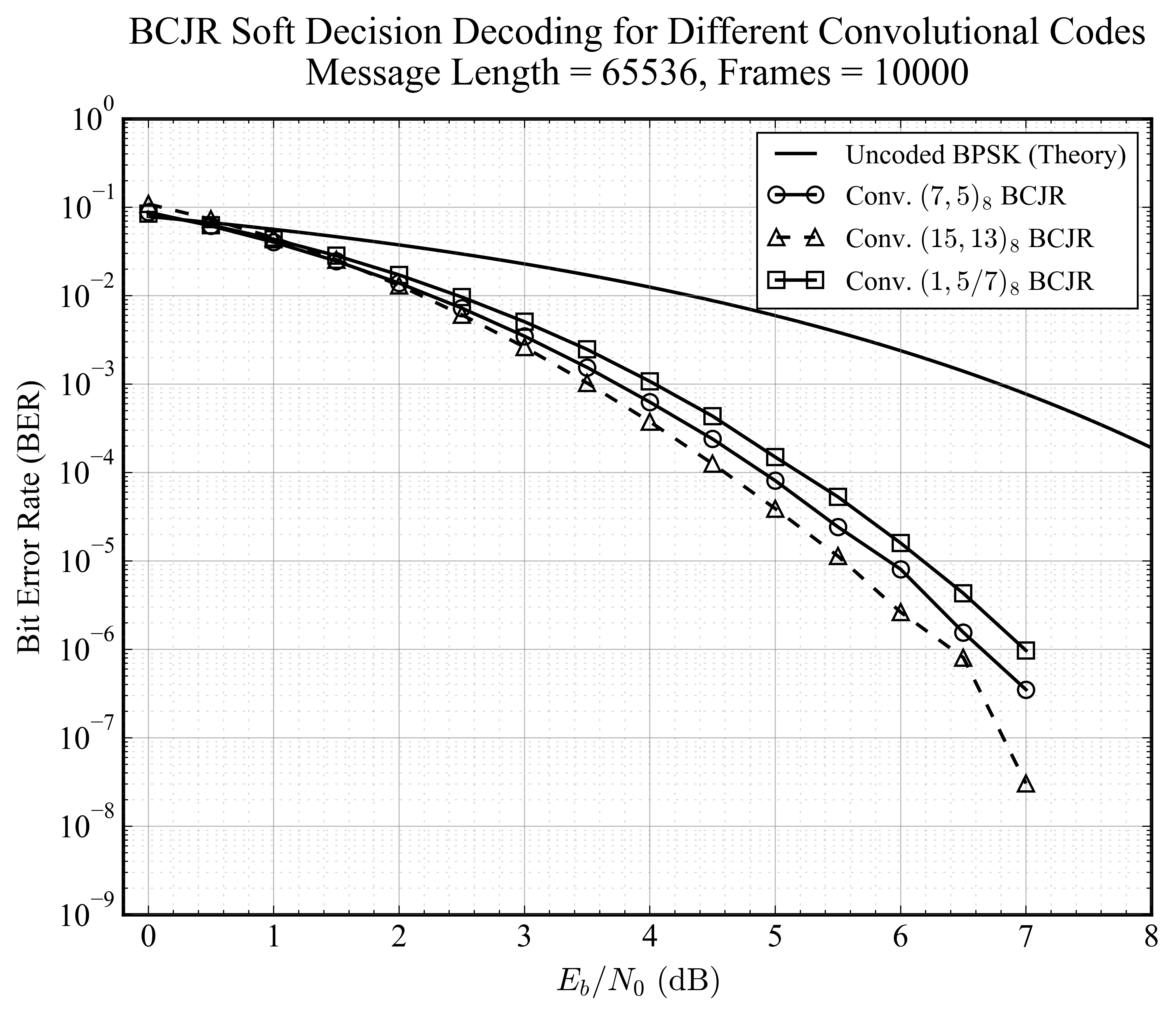
BCJR 算法输出比特级的软信息(LLR),是 Turbo 码迭代译码的核心组件。图中展示了其作为独立译码器时的优异性能。
Turbo 码性能分析
Turbo 码的核心在于迭代译码结构。实验重点探究了交织长度、迭代次数以及级联结构对性能的影响。
码长与交织增益
对比了从短帧(N=256)到长帧(N=16384)的性能变化。
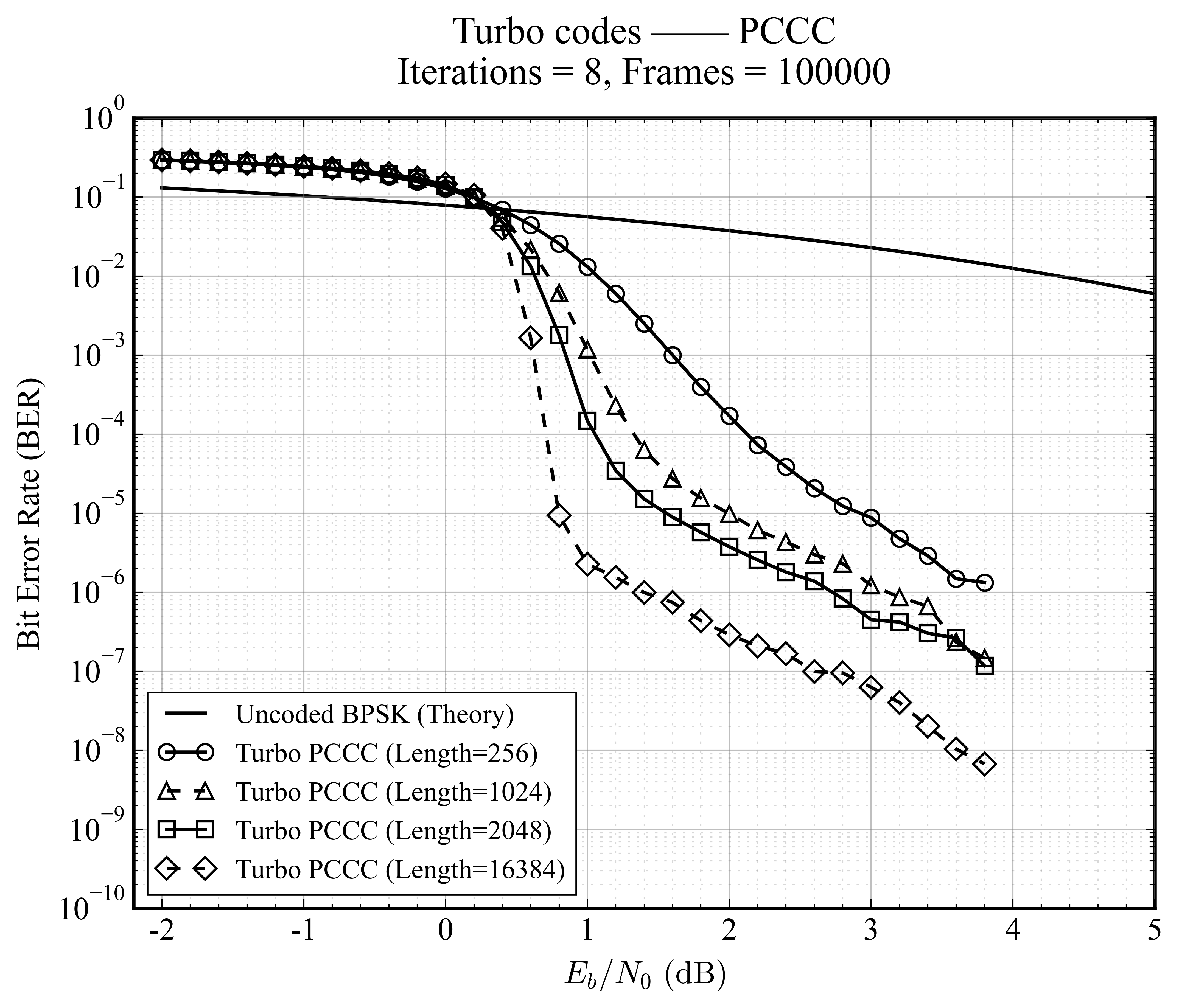
交织器增益现象极其明显。随着码长 N 增加,交织器打散突发错误的能力增强,BER 曲线的”瀑布区”变得更加陡峭,误平层显著降低。
迭代次数的影响
观察 Turbo 码在 1 到 8 次迭代过程中的性能收敛情况。
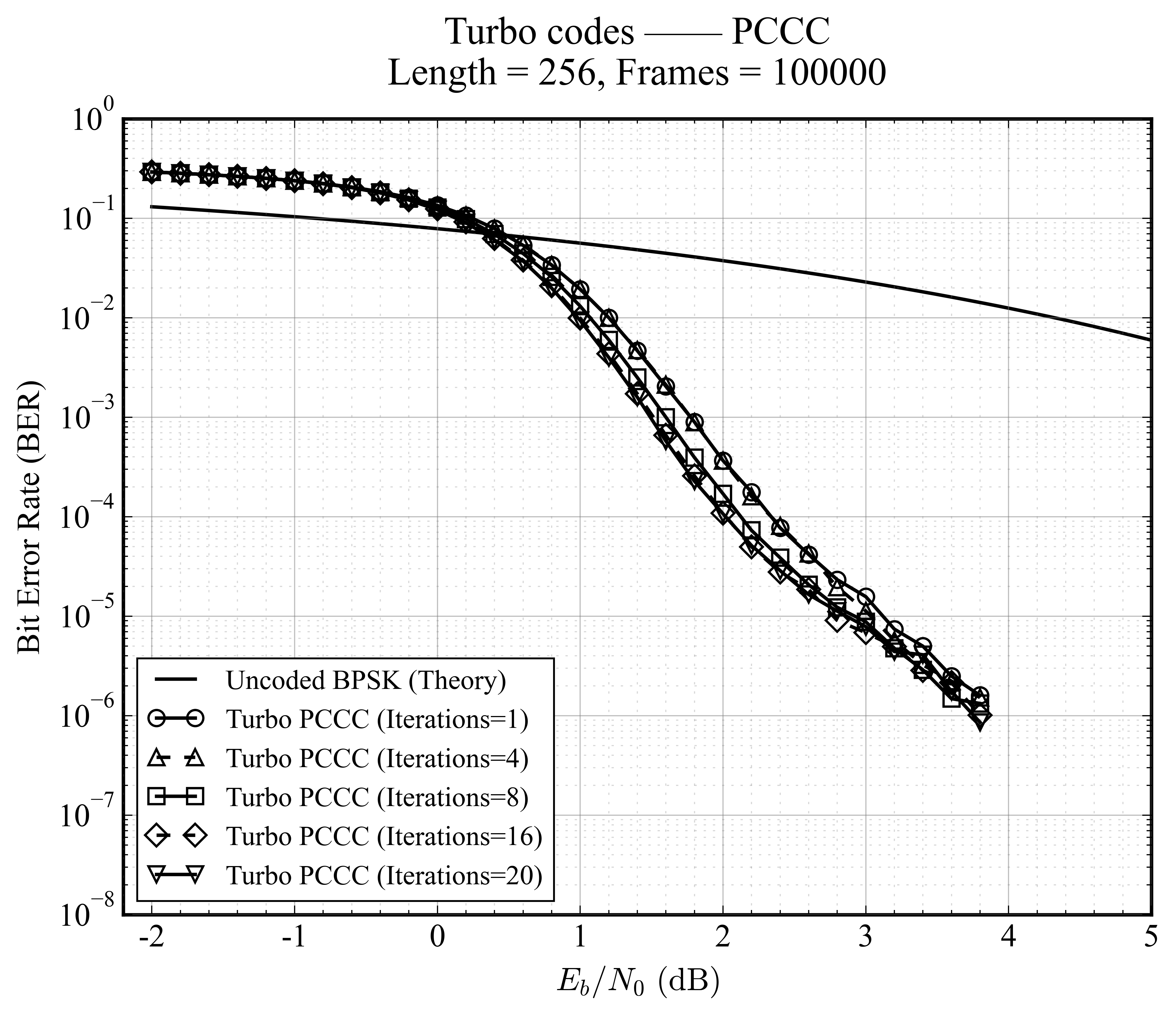
随着迭代次数增加,译码器之间交换的外部信息逐渐精确。通常在 4-8 次迭代后性能趋于饱和,继续增加迭代带来的增益逐渐减小。
SCCC vs PCCC
对比了两种经典的 Turbo 码级联架构。
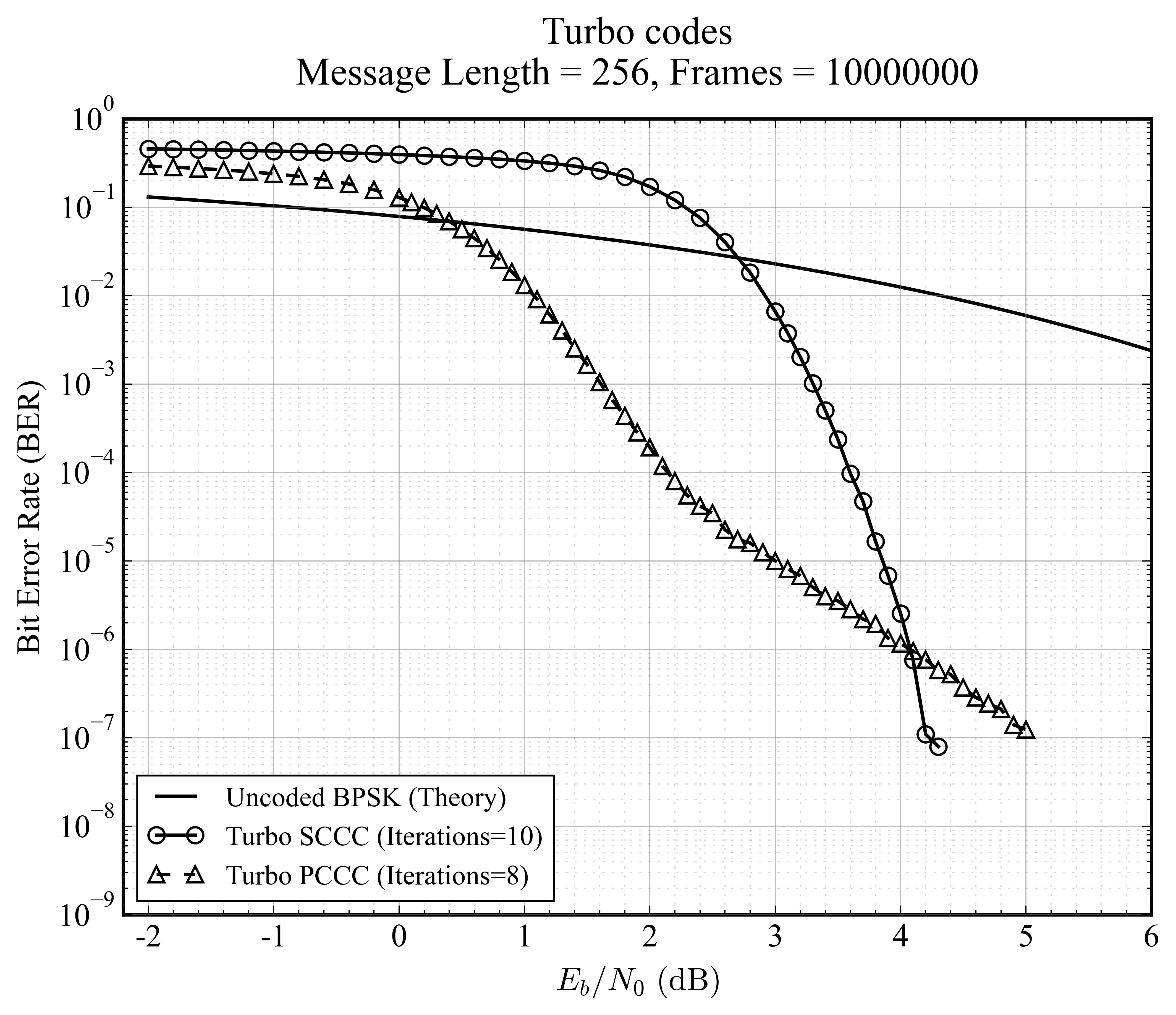
- PCCC(并行级联):经典 Turbo 码结构,瀑布区出现较早(收敛快),但存在较高的误平层。
- SCCC(串行级联):通常具有更低的误平层,适合对误码率要求极高的场景。
项目信息
- 项目仓库:github.com/Yauanyyy/ChannelCoding-Simulations
- 编码与译码算法用 C/C++ 实现,仿真结果由 Python 统一绘图
- 包含 GitHub Actions 自动化仿真流水线